处理器集成丰富的内核
软件通用性的难题有待解决
在提高CPU内核性能方面展开竞争的处理器厂商,在集成各种可编程电路方面也展开了行动。这意味着生产厂商之间的竞争重点发生了变化。
PC处理器将采用集成多个CPU内核和GPU内核,并具有内存控制器的架构。而且,集成更多的外围电路并同时兼顾系统功耗和性能的研发工作,正在取得进展。
AMD公司很早就提出了异构多核处理器的开发计划。公司计划先增加同类型内核的数量,同时增加可在PC中利用的加速器电路的种类。最终,将这些CPU内核和加速器电路集成到一块芯片上。
多核CPU将继续向前发展。2009年,服务器处理器的内核数量最多将增加到16个,PC处理器的内核数量最多将增加到8个。同时,公司也在推进不同类型内核的集成,而且,集成对象不只是GPU内核。AMD公司在2006年10月提出的Fusion方案,可以说是在这之前发布的Torrenza方案的基础上发展起来的。Fusion方案要求,由第三方芯片提供商制造的各种加速器电路必须支持HyperTransport标准,这样就能实现芯片之间的存储器共享。把Torrenza和Fusion这两个方案结合起来,最终就可以将多个同类型的CPU内核和GPU等各种内核集成到一起(见图6)。
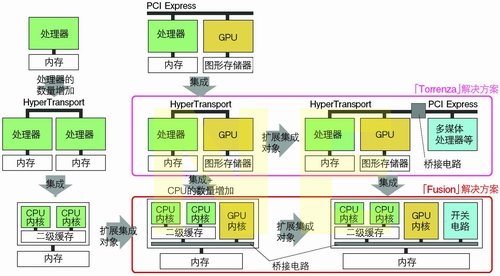
图6 内核数量和集成对象越来越多
在对功耗要求很严格的嵌入式设备中采用的多核SoC,就是由CPU内核和其它内核集成的异构多核架构。这种面向嵌入式设备的SoC,也可能发展为集成多个同类型CPU内核和其它加速器内核的架构。ARM公司已经提出面向下一代家庭网关设备的SoC方案,计划将最多包括4个CPU内核的ARM11 MPCore和GPU内核或视频处理内核等集成在一起。
英特尔公司也表示,其计划在2008年内推出的45nm Nehalem(开发代号)处理器中将会有集成了GPU内核的产品。在Nehalem中,还计划要在处理器内部集成内存控制器。
GPU的通用化是推动力
GPU内核的内部架构在最近1年内发生了很大的变化。在这种变化的驱动下,GPU内核不仅可以用于图形渲染处理,而且还可用作擅长浮点运算的矢量处理器。于是,处理器厂商开始采用GPU内核来弥补CPU内核的缺陷,用它来处理CPU内核所不擅长的那些工作。
2006年11月,NVIDIA公司推出基于G80架构的GeForce 8800 GPU。接着,2007年5月,AMD公司发布了Radeon HD 2000系列GPU产品。这两款产品都采用了先进的统一渲染架构(见图7)。这种架构使GPU的运算单元变得通用,并可以根据图形渲染处理的负载灵活地改变运算单元的任务。
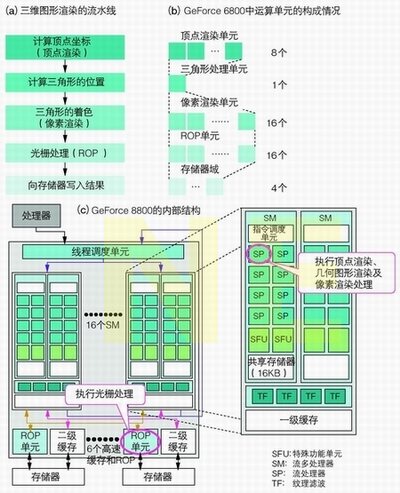
图7 使图形处理电路具有通用性
一般来说,在由许多三角形组成的三维空间中,三维图形渲染处理的执行步骤主要有以下几个:计算顶点坐标;计算三角形的位置;三角形的着色;执行抗混叠处理、颜色和纵向数据的压缩等光栅处理;将处理结果写入存储器。以前,GPU中具有专门为各级处理特别定制的运算单元。GPU生产商会根据通常情况下图形渲染处理的负载来估计各级处理所需的运算单元数量,并予以确定。
但是,在图形渲染处理中,根据表达三维空间的三角形数量或在三角形着色时纹理清晰度的不同,各级处理的负载将会发生变化。在传统结构中,由于各级处理的运算单元数量是事先决定的,因此,在负载发生变化的情况下,固定的运算单元数量会成为阻碍系统整体处理能力提高的瓶颈。
为了打破这样的状况,新的GPU产品采用了统一渲染架构。这种架构集成了多个支持顶点坐标计算及三角形着色等多级处理的运算单元,各运算单元的任务可以根据各级处理的负载进行调整。
新架构的出现带动了在以浮点运算为中心的通用处理中使用GPU的潮流。在采用统一渲染架构之前,GPGPU的构想就已存在,它能在使用OpenG库的同时,提高科学计算的处理速度。采用统一渲染架构后,GPU运算单元可在每次处理时读入指令和数据,通用性得到了提高。因此,这种电路可用于提高物理运算或科学计算中一般性的浮点运算指令的执行速度。
2006年10月,Imagination技术公司推出面向嵌入式设备的GPU内核PowerVR SGX,产品中也采用了统一渲染架构,利用相同的运算单元来处理顶点坐标的计算和三角形的着色工作。该公司CEO Hossein Yassaie认为:“在嵌入式设备领域中,还几乎没有用户计划将PowerVR用作GPGPU。但是,如果该产品能在PC领域中先获得普及的话,这种使用方法就很可能会得到扩展。”
也可以集成信号处理内核
正如AMD公司的Torrenza方案所描述的那样,能够在处理器中集成的内核并不限于GPU,还包括其它各种各样的内核,比如,可高速执行定点数据与、或运算的DSP内核,可替代DSP内核的新结构电路,以及可动态增加或扩展指令的电路和FPGA等。不同应用对于运算种类、性能、功耗以及处理内容的复杂程度等的要求都不同,预计今后各公司将会针对各种应用推出相应产品。
美国Stream Processors公司开发的Storm-1处理器集成了可与DSP抗衡的DPU(数据并行处理)内核,适用于视频编/解码等流媒体数据处理应用。Storm-1中集成了用于运行操作系统的MIPS内核、可并行执行大量互相独立的定点运算处理的运算单元DPU,以及用于向DPU发送指令的MIPS内核(见图8)。它最多可同时对8路像素数为724×480的视频流媒体数据进行H.264编码。由于利用CPU内核执行各种信号处理时的效率很低,如果对于静态/动态画面的处理要求进一步提高,那么,就像面向嵌入式应用的SoC中有许多产品都集成了DSP内核一样,x86处理器也有可能要集成DSP等用于信号处理的内核。
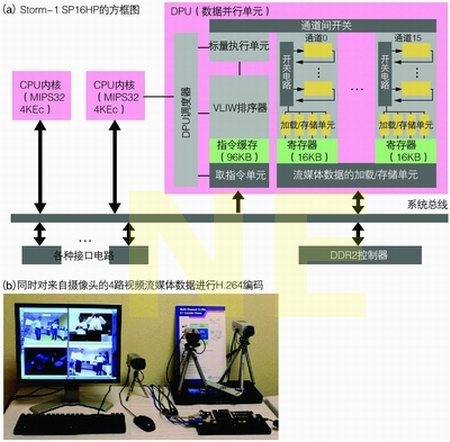
图8 集成加速器以提高信号处理的速度
另一方面,集成有多个同类型CPU内核的处理器,在某些应用中也可能具有足够的性能,如经常并行执行多个应用软件或多个线程的应用。今后,处理器技术的发展方向将不仅是集成不同类型的内核,也会针对特定应用集成更多同类型的内核。
软件开发工具逐步完善
为了利用加速器电路提高CPU内核所不擅长的处理工作的速度,必须完善软件开发环境。为此,英特尔和NVIDIA公司分别推出了开发工具:英特尔公司的开发工具CHI(C for Heterogeneous Integration),适于开发在异构多核处理器中运行的程序;NVIDIA公司的开发工具CUDA,适于开发在G80架构的GPU中运行的程序。这两种开发工具都能在同一个环境中开发出可根据需要为CPU内核和加速器电路分配任务的软件。
英特尔公司的CHI工具使用C/C++语言编写程序,并使用加速器特定汇编程序把其中明确标出的供加速器处理的内容转换成目标代码,该目标代码支持面向加速器应用的扩展指令集结构Accelerator Exoskeleton(加速器外骨骼)。在CHI工具中,CPU内核和加速器电路具有共享的虚拟存储器空间,并在其中交换数据,同时执行处理(见图9)。在英特尔公司的构想中,加速器电路包括进行图形处理的可编程内核GMA X3000,或是专为无线通信的基带处理而优化的可配置内核等。
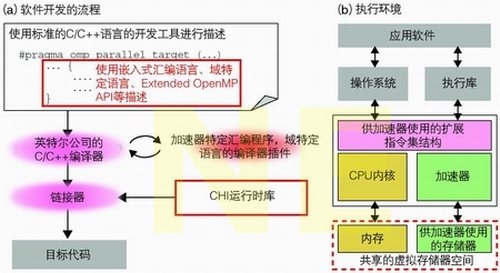
图9 完善面向非对称型多核架构的开发环境
过去,处理器和加速器电路采用的是不同的芯片,由于加速器和处理器上运行的程序是由不同的语言编写的,因此,必须分别进行编译,导致开发工程师分散。而且,在运行时,CPU一侧的程序需要通过设备驱动程序的接口来传送运行内容和数据,导致处理时的工作量增加。CHI的目标就是解决这两方面的问题。
NVIDIA公司提供的CUDA工具则主要是为了解决开发工程师分散的问题。为了配合公司通用计算新产品Tesla系列GPU的推出,NVIDIA开始免费提供CUDA。CUDA使用C语言编写在CPU和GPU上运行的程序,编译器可自动生成CPU和GPU的目标代码。软件工程师只需要描述出需要在GPU中执行的处理,以及在GPU使用的存储器和内存间如何交换数据即可(见图10)。图10中给出了求矩阵[A]和矩阵[B]乘积的源代码。

图10 利用CUDA进行软件开发
处理流程如下:首先,处理器会将需要的数据复制到供GPU使用的存储器中,并调用在GPU中执行的函数;然后,GPU根据处理器的指令,对互相独立的数据使用多个内核进行并行处理;最后,处理器会从GPU所使用的存储器中获得处理结果。
担心失去通用性
虽然异构多核处理器在硬件架构和软件开发环境的完善方面取得了上述进展,但是,新的挑战正在浮现:PC处理器的最大优点——通用性将可能会因为软件问题而消失。也就是说,一些面向特定处理器开发的软件,在异构多核处理器中很有可能无法正常工作,或者说不能实现原本应该达到的整体处理能力。这样,以x86指令集为基础而发展起来的庞大的软件生态系统,也许会因为处理器中集成了新的内核或用于新的应用而断裂。
如果被集成的GPU内核只是用于图形处理,那就不会有太大问题,因为OpenGL或DirectX等标准API可以确保程序的正常运行。在利用GPU进行图形渲染处理时,应用软件开发工程师会使用OpenGL或DirectX来描述由GPU执行的任务。即使改用其它的GPU,OpenGL等API以下层次的差异化问题也可以交由设备驱动程序来解决。虽然处理速度会有差别,但通常不会发生软件无法正常工作的问题。
不过,在利用GPU进行物理运算或科学计算,或是利用处理器中集成的特殊内核等情况中,并不存在标准的API。因此,使用某个处理器的专用开发环境开发的软件,在其它处理器上就有可能无法工作(见图11)。
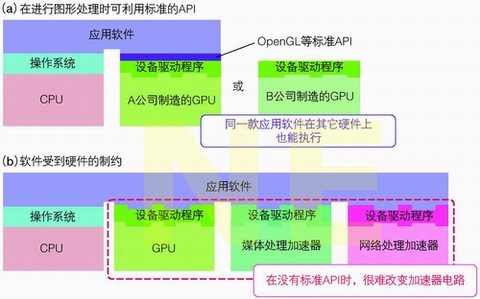
图11 可能失去以前的通用性
处理器厂商也意识到这个问题。2007年9月,英特尔公司宣布收购爱尔兰Havok公司,这家公司开发了面向游戏机等应用的物理运算库。这一行动表明,对于今后处理器的发展来说,必须设法完善软件库。
对于索尼、东芝及IBM公司合作开发的异构多核处理器Cell,参与开发的工程师认为:“在使用Cell中集成的信号处理器SPE时,自行编制库的软件工程师并不多,而且进行实际开发时工作量很大。为了使更多的开发者能充分发挥新架构处理器的作用,必须设法完善标准库。”
在手机软件方面,Khronos集团正在推进媒体应用的标准API——OpenKODE的开发工作。其最初的目标是解决CPU内核的指令集架构的差异性问题。但现在,Khronos则计划扩展应用对象,将其用于实现GPU内核等硬件的通用化。在由不同类型的内核构成的x86处理器中,可能也必须采取这样的行动。AMD公司的CTO Phil Hester表示:“缺乏标准的API和库是GPGPU需要解决的问题之一,我们打算和各种团体合作推进面向科学计算和物理运算的库的建立工作。”
彻底改变架构 开拓同构多核道路
在异构多核处理器的开发工作之外,业内各公司也在积极寻求同构多核处理器的解决方案。2007年8月,美国Tilera公司推出面向嵌入式设备的处理器TILE64,其中集成了64个网格状排列的3路VLIW CPU内核。另外,2006年秋,英特尔公司也发布了集成有80个CPU内核的处理器,用于技术研发,每个CPU内核中具有2个浮点运算器。利用这种芯片,英特尔正在继续研究集成多个CPU内核的处理器内部架构。
Tilera公司和英特尔公司的处理器在CPU内核之间都采用了网格状的连接结构(见图A-1)。因此,内核间以及内核和存储器控制器间的通信已不再是阻碍整体处理能力提高的瓶颈。
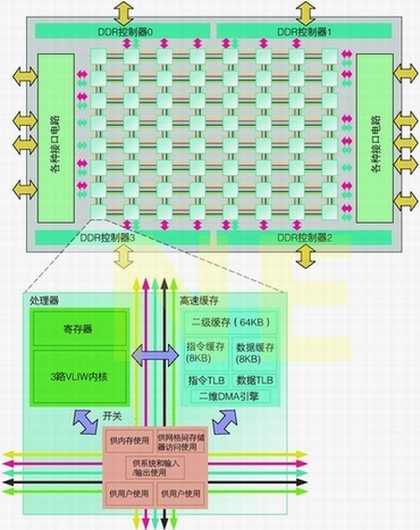
图A-1 出现彻底改变架构的方案
上述架构适于生成多个线程的应用,或是执行流媒体数据处理的应用。但是,处理流媒体数据时,必须实现流水线的并行处理;处理独立数据时,必须利用多个线程执行。由于软件的开发方法及执行环境发生了很大变化,因此,软件工程师及设备厂商可能需要一段时间才能适应。最近,并行编程技术受到关注,而且,对于新的软件开发方法的研究也正在取得进展。如果便于并行编程的环境得到完善,上述架构也许会顺利得到普及。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
